声優人名変換 MS-IME ユーザー辞書
辞書概要
Wikipedia のカテゴリ日本の男性声優、日本の女性声優に登録されている人物の人名と読みを自動抽出し、ユーザー辞書 (MS-IME 形式) を作成しました。
2020/05/23 版の辞書には 男性声優3,554名、女性声優4,458名 が登録されています。
人名と読みに加え、その声優さんの概略をコメントとして登録可能なので、文字変換を利用して簡単なプロフィール確認も可能です。
MS-IME 形式の辞書の読み込みに対応していれば、他の変換ソフトでも活用可能です (ATOK にて利用できることは確認済みです)。
< MS-IME における使用例 >
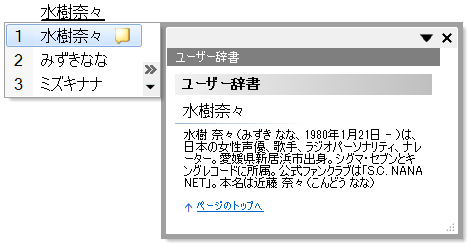
ダウンロード
2020/05/23 版 seiyu_dictionary_20200523.zip
2018/03/26 版 seiyu_dictionary_20180326.zip
仕様等
MS-IME 2010 の単語登録におけるコメント文字数上限が128文字、ATOK 2013 では上限が100文字なので、「コメントあり」のものはその上限文字数以下に収まるように調整してあります。
文字数上限を超えたデータを登録しようとすると登録失敗する場合があるので、ご注意ください。
ATOK 環境においては、長いコメントは変換時に邪魔に見える可能性が高いです。ATOK ユーザーのみなさんは、「コメント省略版」のものを登録することをおすすめします。
また、姓名の読みを正常に自動抽出できた人名のみが登録されています。特にひらがな表記・アルファベット表記の声優さんは正常に読みが抽出できず、Wikipedia に項目があっても、この辞書には登録がない場合があります(例:かかずゆみ、こやまきみこ、Pile など)。ご了承ください。2020/05/23 版にて、それなりに改善されたと思われます。
なお、辞書テキストデータの文字コードは Unicode です。
自動抽出方法など
どのようにしてこの辞書データを作成したか、簡単にメモしておきます (主に自分のために)。
単に辞書を利用したいだけの方は、ここから先を読む必要はないと思います。
1. 姓名と読みの抽出
先人の知恵に甘えろ…ということで、中身の細部を確認も理解もしないまま、下記リンクのものを活用しました。ありがとうございました。
Wikipediaから人名(姓・名別、読みつき)を取り出す - アスペ日記
GitHub - hiroshi-manabe/extract_jawp_names: Extracts personal names in Wikipedia Japanese.
GitHub のオリジナルのコードは日本語版 Wikipedia に登録されているすべての人物が対象になっているので、extract_jawp_names.pl の15行目 Category 判定部分を(男性声優)、(女性声優)に書き換えて処理しました。
なお、ひらがな表記・アルファベット表記の声優さんは正常に読みが抽出できない、という問題はこのコード由来のものです。
(というか、Wikipedia が「読みがな」に関するテンプレートを確立していないのが根本的な原因だと思いますが…。)
ちなみに、今回の辞書に関して、姓・名を分離した人名・読みデータも手元にありますが、それをすべて登録すると、却って適切な変換の妨げになると思うので、公開は割愛しています。
Windows 環境における実行については、Windows Subsystem for Linux の Ubuntu でうまくいきました。
[2020/05/23] 一部の人名しか抽出がうまくいかなくなっていたので、pl ファイル末尾の while ループ処理を書き換えてみました(姓/名の分離は諦めました)。extract_jawp_names_miso253_20200523.zip
2. abstract の抽出
先人の知恵に甘えろ…ということで、中身の細部を確認も理解もしないまま、下記リンクのものを活用しました。ありがとうございました。
Wikipedia からスクレイピングして… とか言ってる人におすすめしたい,DBPedia からの情報抽出 - Qiita
Virtuoso SPARQL Query Editor
「Category:東証一部上場企業」の概略抽出サンプルコードがあったので、何も考えずに心を無にして「Category:日本の男性声優」「Category:日本の女性声優」に書き換えればうまくいきました。
ちなみに、この方法で得た概略データから適当に姓名と読みの抽出を行うことができれば、1. の抽出は行わなくても概略コメント付き変換辞書の作成が可能です。記事中における「読み」の記載方法が統一されていないので、地味にめんどくさい&精度を高めるのが一苦労だと思いますが…。
それにしても、DBPedia のまともな活用ができたら、ちょっと楽しそうです。なんかよく分からんけど、楽しそうです(よく分からんけど)。
3. 抽出データの整理
上述の抽出データを Excel で適当に整理して MS-IME 辞書形式にしました。例によって理解もしないまま、下記リンクのものを活用しました。ありがとうございました。
Excelのワークシート関数で正規表現を使う - Qiita
正規表現チェッカー PHP: preg_match() / JavaScript: match()
VBScript はサクサク書けたら便利そうな気がしますが、機会がなくてまともに書いたことなしです。困ったものです。
正規表現はたまにしか使わないので、なかなか覚えられないです。困ったものです。
そんなこんなで、以上のような既存の便利なものを適当に動かしてみたら、それっぽい辞書が完成しました。やったー!
年に一度ぐらいは辞書を更新したほうがいい気もしますが、私がマメに更新するかは不明です。
マメに更新する人がいれば、勝手に更新して公開してほしいです。(私も活用したいので、公開した際には教えてもらえるとうれしいです。)
サイトTOPへ